")



Этапы настройки
Настройка и запуск системы SoftPI Flow Collector производится в программе "Настройка коллектора сетевых потоков", и этот процесс состоит из следующих этапов:
- настройка параметров сбора данных (компонент "Сбор данных");
- определиться, какой тип хранилища будет использоваться. В случае если в качестве хранилища предполагается Microsoft SQL Server или MySQL, необходимо загрузить инсталляцию соответствующего SQl сервера и установить на компьютере*;
- настройка параметров хранилища данных (компонент "Хранилище");
- настройка параметров агрегации при необходимости ( компонент "Агрегация");
- запуск службы (компонент "Служба").
Настройка параметров сбора данных
Запустите программу "Настройка коллектора сетевых потоков" и выберите компонент "Сбор данных". Программа примет вид, как показано на рисунке ниже.
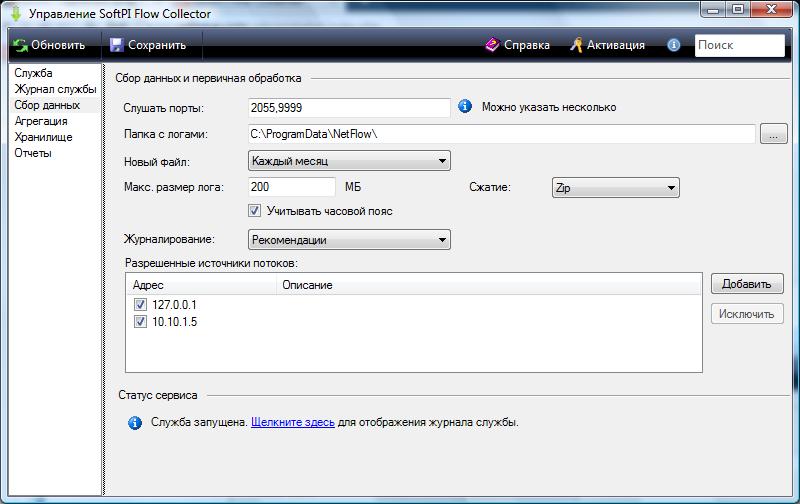
В позиции "Слушать порты" введите перечень IP портов, которые должны использоваться для приема данных службой Flow Collector (служба работает только с использованием UDP протокола). В случае использования более одного порта их номера должны вводится через запятую. По умолчанию задан IP порт 2055, который обычно используется для NetFlow протокола. Для IPFIX протокола в соответствии с RFC 5101 должен использоваться порт 4739 для незащищенного соединения, которое выполняется через UDP протокол. Однако, не все производители придерживаются этого требования. Поэтому следует в документации на телекоммуникационное оборудование точно определить номер IP порта, который используется для передачи данных NetFlow, IPFIX или RFlow протоколов.
Flow коллектор кроме обработки поступающего потока данных и записи его в хранилище выполняет резервное копирование потока данных в бинарный файл в том виде, в каком эти данные поступили на сетевой интерфейс.
В позиции "Папка с логами" можно изменить путь к папке, куда будут записываться файлы с бинарной информацией, полученной от телекоммуникационного устройства. По умолчанию задается папка: \ProgramData\NetFlow\
Выберите в списке "Новый файл" период создания нового лог файла для бинарных данных, получаемых от телекоммуникационного устройства. Возможные варианты выбора:
- Не создавать;
- Каждый час;
- Каждый день;
- Каждый месяц.
Вне зависимости от выбранного периода в позиции "Новый файл" можно в позиции "Макс. размер лога" определить размер лог файла, по достижении которого будет создаваться новый файл. По умолчанию используется значение: 200 Мбайт.
Для уменьшения объема, занимаемого лог файлом, можно выполнять его сжатие. Сжатие выполняется сразу же при записи данных в файл. Возможно использование различных алгоритмов сжатия данных, что определяется выбором в списке "Сжатие". Возможные варианты:
- Без сжатия;
- Zip;
- Bzip;
- Zlib.
Служба Flow Collector может вести журнал результатов своей работы с различной степенью детализации. Степень детализации определяется значением параметра, заданного в списке "Журналирование". Возможны следующие варианты:
- Статус,
- Критические ошибки,
- Ошибки,
- Предупреждения,
- Информация,
- Рекомендации,
- Отладка.
"Статус" — это наименее детальный уровень. "Отладка" — наиболее детальный уровень, например, отображается IP адреса устройств, с которых поступают данные. По умолчанию задается уровень "Информация".
Задайте в разделе "Разрешенные источники потоков" IP адреса телекоммуникационных устройств, с которых служба Flow Collector должна получать информацию. Для добавления нового IP адреса щелкните по кнопке "Добавить". Появится окно "Источник данных", показанное на рисунке ниже.
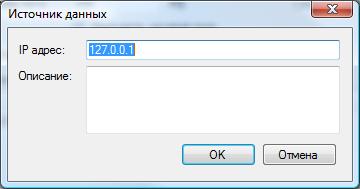
позиции "IP адрес" введите IP адрес требуемого устройства.
Позиция "Описание" носит информационный характер и не обязательна для ввода.
Примечание. Служба Flow Collector может сама добавлять в список "Разрешенные источники потоков" IP адреса телекоммуникационных устройств, от которых поступают данные. Но если для конкретного устройства не установлен флаг в этом списке, данные с этого устройства не будут обрабатываться. Соответственно, для обработки данных с требуемых источников данных установите флаг в столбце "Адрес".
После ввода всех перечисленных выше параметров щелкните по кнопке "Сохранить", которая находится на панели инструментов программы.
Настройка параметров хранилища данных
Как указывалось выше, перед настройкой параметров хранилища, пользователь должен определиться, какой тип хранилища будет использоваться. В случае если в качестве хранилища предполагается использовать Microsoft SQL Server или MySQL, необходимо загрузить соответствующую инсталляцию и установить на компьютере.
Рекомендуем использовать в качестве хранилища Microsoft SQL Server 2014 или 2012. При использовании любого из этих серверов в качестве хранилища и выборе полей для сохранения информации о сетевых потоках, аналогичных полям протокола NetFlow версии 5, пользователю Flow Collector будет доступен режим "Отчеты". В противном случае пользователь должен сам найти приложение, которое обеспечит получение отчетов из требуемого хранилища информации.
Выберите компонент "Хранилище". При этом программа примет вид, подобный показанному на рисунке ниже.
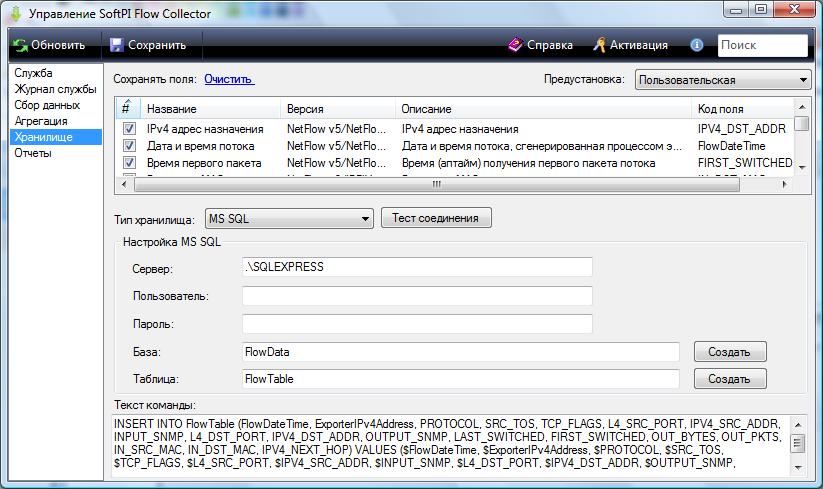
Определите перечень полей, которые будут обрабатываться и сохраняться в хранилище информации. Для этого можно воспользоваться предустановленными наборами полей. Выбор предустановленных наборов полей выполняется в списке "Предустановка".
Можно выбрать один из следующих вариантов:
- Основные NetFlow v5 – обеспечивается выбор наиболее часто используемых полей протокола NetFlow версии 5;
- Основные NetFlow v9 - обеспечивается выбор наиболее часто используемых полей протокола NetFlow версии 9;
- Основные IPFIX - обеспечивается выбор наиболее часто используемых полей протокола IPFIX;
- Все NetFlow v5 - обеспечивается выбор всех полей протокола NetFlow версии 5;
- Все NetFlow v9 - обеспечивается выбор всех полей протокола NetFlow версии 9;
- Все IPFIX - обеспечивается выбор всех полей протокола IPFIX.
Если пользователя интересует какой-либо специфический набор, который не соответствует ни одному из перечисленных выше, пользователь может сам выбрать требуемые поля, установив флаги в столбце "#", в требуемых строках таблицы.
Если пользователь планирует получать данные от нескольких сетевых устройств, которые используют различные протоколы, то соответственно, необходимо выбрать поля, поддерживаемые во всех требуемых типах протоколов.
Таблица полей содержит следующие столбцы:
- # - показывает выбрано или нет это поле.
- Название — отображает название поля;
- Версия — отображает тип протокола и версию, к которому относится конкретное поле;
- Описание — приводится краткое описание поля;
- Код поля — имя поля, которое используется в базе данных. Это имя также используется в позиции "Текст команды" для автоматического создания запроса к базе данных для записи данных.
Таблица поддерживает возможности сортировки информации. Для этого необходимо щелкнуть по наименовании интересующего столбца.
Щелчок правой кнопкой мыши по строке таблице с наименованиями столбцов приводит к появлению меню, подобного тому, которое показанного на рисунке.
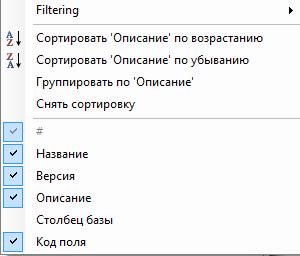
Filtering " - выбор этого пункта меню приводит к появлению дополнительного меню, в котором пользователь должен установить флаги напротив букв, которые являются первыми в наименования любого из полей. Это приводит к соответствующей фильтрации информации.
"Сортировать 'ХХХХ' по возрастанию". Позволяет отсортировать по возрастанию поле 'ХХХХ'. Выбранное поле 'ХХХХ' определяется тем, на наименовании какого из столбцов находился курсор в момент выполнения щелчка для вызова меню.
"Сортировать 'ХХХХ' по убыванию". Позволяет отсортировать по убыванию поле 'ХХХХ'.
"Группировать по 'ХХХХ'". Позволяет сгруппировать данные в таблице по первым буквам слов в выбранном столбце.
"Фиксировать группировку по 'ХХХХ'". Появляется в меню только после того, как установлена группировка по какому-либо столбцу. Этот режим меню отключает дальнейшую сортировку информации в таблице. Отключается этот пункт с помощью пункта меню "Отключить группировку".
"Отключить группировку". Отключает предварительно установленный режим группировки данных в таблице.
Для быстрого поиска требуемого параметра в таблице рекомендуется использовать режим поиска. Он осуществляется путем ввода искомой информации в позицию со словом "Поиск", расположенной в правой части панели инструментов программы.
В том случае, если для анализа накопленных данных пользователь планирует воспользоваться возможностями режима "Отчеты" программы "Настройка коллектора сетевых потоков", то необходимо:
- выбрать в позиции "Тип хранилища" значение "MS SQL";
- выбрать в качестве полей, поля протокола NetFlow версии 5.
В списке "Тип хранилища" возможны следующие варианты:
- MS SQL – используется для хранилища на базе Microsoft SQL Server 2014/2012/2008/2005/2000. Если вы не имеете приобретенного Microsoft SQL Server и не планируете его приобретение, то рекомендуем использовать бесплатную редакцию Express для Microsoft SQL Server 2014/2012.
- MySQL – используется для хранилища с соответствующим наименованием,
- CSV file – в качестве хранилища используется текстовый файл с разделителями (формат файла — CSV).
Если выбрали значение MS SQL, то в позиции "Сервер" введите наименование сервера или его IP адрес (при необходимости с именем сервера).
В позициях "Пользователь", "Пароль" введите соответственно имя пользователя и его пароль, с которыми служба Flow Collector будет подключаться к SQL серверу. При использовании Microsoft SQL Server на том же компьютере, где производится настройка и будет работать служба Flow Collector, по умолчанию будет использоваться Windows аутентификация. В этом случае ввод имени пользователя и пароля не нужен.
В позиции "База" введите наименование базы данных, в которую будут помещаться данные. При первоначальной настройке такую базу нужно создать. Для этого щелкните по кнопке "Создать", которая находится в той же строке, что и позиция "База". В случае успешного завершения операции создания базы данных на экране появится сообщение: "База данных 'xxxxxxxx' создана успешно", где xxxxхxxx – наименование базы данных.
В позиции "Таблица" введите наименование таблицы в созданной базе данных, в которую будут помещаться данные. При первоначальной настройке такую таблицу нужно создать. Для этого щелкните по кнопке "Создать", которая находится в той же строке, что и позиция "Таблица". Появится окно, подобное тому, которое показано на рисунке ниже.
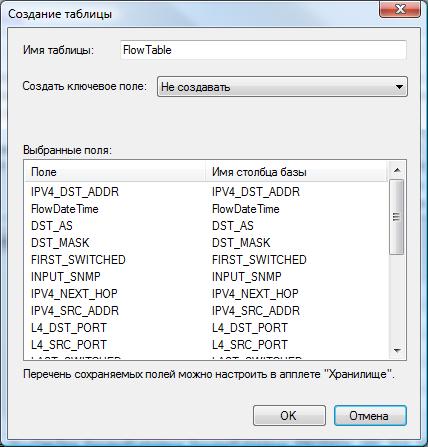
Позиция "Имя таблицы" отображает имя создаваемой таблицы.
Таблица "Выбранные поля" содержит поля, которые пользователь выбрал в окне, показанном на рисунке компонента "Хранилище".
Поле "Создать ключевое поле" используется для задания ключевого поля в таблице, которое в дальнейшем при выборках данных из таблицы позволяет выбрать конкретную запись по ее уникальному идентификатору (ключевому слову). Возможны следующие варианты:
- Не создавать. Используется по умолчанию, когда не предполагается выполнять указанные выше выборки. Отсутствие ключевого поля позволяет несколько снизить объем базы данных.
- bigint. Формат bigint рекомендуется устанавливать при необходимости в ключевом поле и относительно невысоком трафике и соответствующем объеме информации, поступающей в базу данных.
- GUID. Глобальный уникальный 128-и битовый идентификатор. Рекомендуется его использовать при необходимости в ключевом поле и высоком трафике, которому соответствует большой объем информации, поступающей в базу данных.
После выбора требуемых параметров, щелкните по кнопке "ОК". В случае успешного завершения операции создания таблицы на экране появится сообщение: "Таблица 'xxxxxxxx' успешно создана", где xxxxxxx – наименование таблицы.
Для проверки правильности заданных параметров Microsoft SQL Server-а щелкните по кнопке "Тест соединения". В случае удачного соединения с SQL сервером появится сообщение: "Соединение проверено". При неудачной попытке подключения следует проверить правильность введенных параметром.
В случае выбора в списке "Тип хранилища" значения "MySQL" рядом с позицией "Сервер" появляется позиция "Порт", где задается номер IP порта, по которому осуществляется подключение к MySQL серверу. По умолчанию в этом поле установлено значение: 3306.
В случае выбора в списке "Тип хранилища" значения "CSV file" окно программы частично меняет вид, как показано на рисуноке ниже.
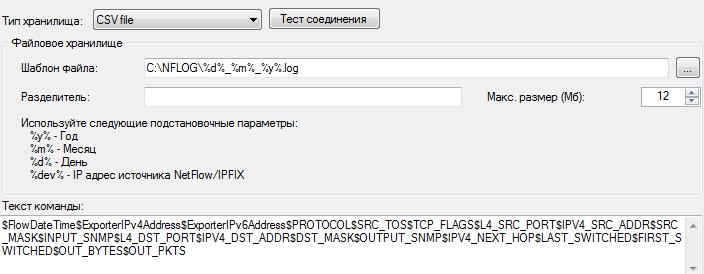
В позиции "Шаблон" задаются путь и шаблон для наименования файла. При этом для задания имени файла используются следующие обозначения:
%y% - год;
%m% - месяц;
%d% - день;
%dev% - IP адрес оборудования, с которого собираются данные.
Файл по умолчанию имеет расширение log.
В позиции "Разделитель" пользователь может ввести символ разделителя полей в файле.
В позиции "Макс. размер" задается максимально допустимый размер файла. При достижении установленного значения автоматически будет создан новый файл.
После задания всех требуемых параметров в компоненте "Хранилище" щелкните по кнопке "Сохранить" на панели инструментов программы.
Настройка параметров агрегации
Настройку параметров агрегации следует выполнять, когда планируется агрегировать данные по какому-то из полей. Применение агрегации порой позволяет существенно снизить объем базы данных, но за счет потери полной детализации.
Для установки параметров агрегации выберите компонент "Агрегация". Окно программы примет вид, подобный рисунку.
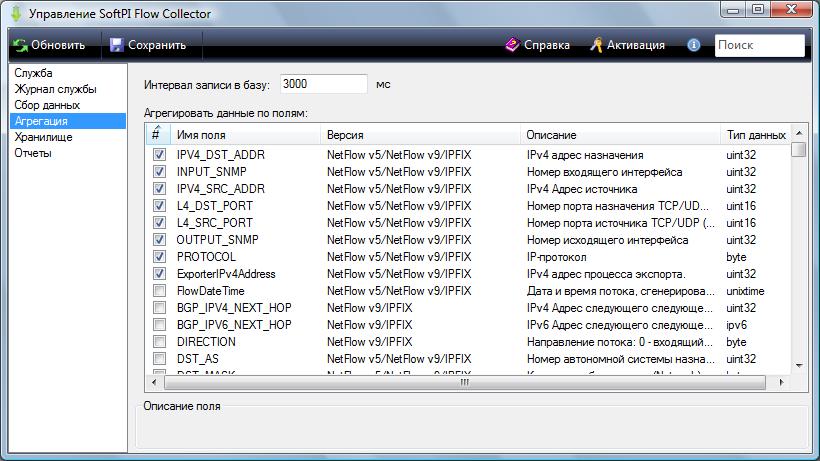
Пользователь может установить агрегацию по любому из полей, указанных в таблице "Агрегировать данные по полям". Таблица содержит 4-е столбца:
- #. Используется для выбора или отмены выбора конкретного поля.
- Имя поля. Отображает имя поля.
- Версия. Отображается тип протокола и номер версии, к которым принадлежит поле.
- Описание. Приводится краткое описание поля.
- Тип данных. Указывается тип данных, которые хранятся в конкретном поле.
Внимание. По умолчанию установлено агрегирование по ряду полей. Если вы не нуждаетесь в таком агрегировании, то удалите флажки с выбранных полей.
Значение по умолчанию для параметра "Интервал записи в базу" составляет 3000 миллисекунд. Пользователь может по своему усмотрению изменить период записи в базу данных. При этом следует иметь в виду, что уменьшение значения интервала записи в базу приводит к увеличению нагрузки на процессор компьютера. Увеличение этого интервала снижает нагрузку на процессор, но пользователь в течение этого интервала не может иметь доступа к данным полученным в этот период и, соответственно, их анализировать.
В случае задания нескольких полей для агрегирования, агрегирование будет выполняться для совокупности заданных полей.
Для работы с данными таблицы (сортировка, группирование, поиск) применимы те же методы, которые описаны для таблицы компонента "Хранилище".
Установка и запуск службы Flow Collector
Для установки и запуска службы Flow Collector выберите компонент "Служба" в программе "Настройка коллектора сетевых потоков". Окно программы примет вид, показанный на рисунке.
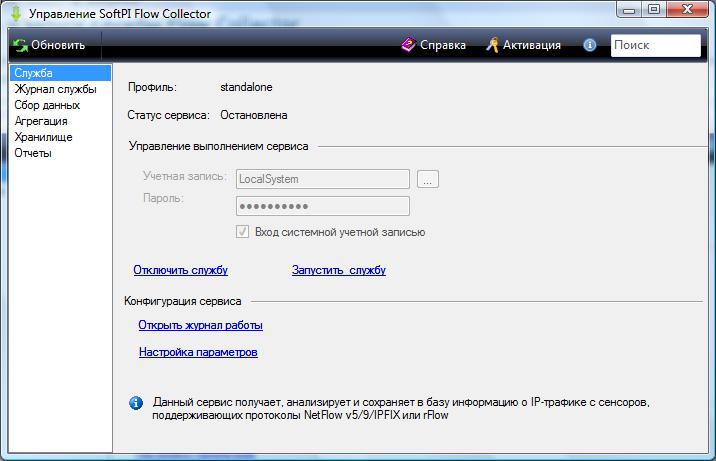
В позиции "Статус сервиса" отображается текущее состояния службы.
Для запуска службы щелкните по ссылке "Запустить службу". При удачном запуске эта ссылка будет заменена на "Остановить службу", а ссылка отключить службу станет неактивной.
Для остановки службы щелкните по ссылке "Остановить службу". После остановки службы ссылка изменить свое значение на "Запустить службу" и станет активной ссылка "Отключить службу".
Для отслеживания подробностей работы службы Flow Collector щелкните по ссылке "Открыть журнал работы" или же выберите этот компонент в перечне компонентов программы.
Ссылка "Настройка параметров" приводит к переходу программы для работы с компонентом "Сбор данных".


